Acorn Pal

Foreward
I am excited to participate in Backdrop Build v3, a program focused on helping builders go from "idea" to "launch" in just four weeks.
In this post, I'll recap what I've done in the first week of the program, both on the technical side and refining the product idea.
Motivation
LLM-based tools have penetrated my day-to-day workflows:
-
ChatGPT: I frequently copy console errors, function bodies, and snippets of documentation into ChatGPT in order to ask, "How do I fix this?" or command it, "Write a bash script to doXto all theYs in this directory". -
Copilot: I use copilot.el, an emacs package that integrates with Github Copilot. -
Warp: I haven't made the switch to using Warp terminal full time, because I ran into some setup issues with their Linux build, but I want to. I use it on the rare occasion I switch to my Mac OS machine and I miss it when I don't have it.
As helpful as these tools are, there's a lot of room for improvement. My two main pain points are:
-
For the LLM to be helpful, I have to manually gather the context it needs to answer my question well. There's no easy way for me to tell it to ingest my project files, terminal session, and online docs into a Vector Database and then augment my prompt with document fragments. In other words, they don't make retreival augmented generation convenient.
-
ChatGPT,Copilot,Warpand Cursor (which I didn't mention above because I don't use, but has some of the features I want in my own editor) are all closed source. I can't change them. I can't learn from them. I can't extend them. I can't make them my own. There's a lot to say about the tradeoffs of open source, but I personally find it pretty frustrating how little control I have over what these tools do, how my data is being used, and which models are running on the backend.
These problems were floating around my head when I was invited to join Backdrop Build v3. When I applied, I pitched an idea for a self-managed server application with an emacs client that solved these problems. I'm calling it Acorn Pal.
Acorn Pal
Acorn PAL is a Project-Aware LLM. It is an “AI buddy” that helps developers navigate and understand unfamiliar codebases.
acorn-pal-brainis the central component of the system. It exposes APIs for ingesting project files, querying LLMs with RAG, generating file summaries, and other helpful tasks.acorn-pal-emacsis an Emacs editor package that integrates the capabilities ofacorn-pal-braindirectly into the developer’s workflow. It defines commands, buffers, and modes for interacting withacorn-pal-brain.
The interface for acorn-pal-emacs will be heavily inspired by magit, and emacs package for interacting with git repositories. Like org-mode, it's one of those packages that make outsides want to join the church of emacs. At the time of this writing, it's the second most popular emacs package, behind only dash, which I have never heard of before today, and which I imagine must be preinstalled in every popular emacs distribution (doom, spacemacs, etc):
Magit adds several commands, buffers, and workflows to emacs. It doesn't just help the git wizards out there -- It also helps you learn. Its interface shows you what commands are available, what the options for those commands are for, and documentation for any command or option is always one keypress away.
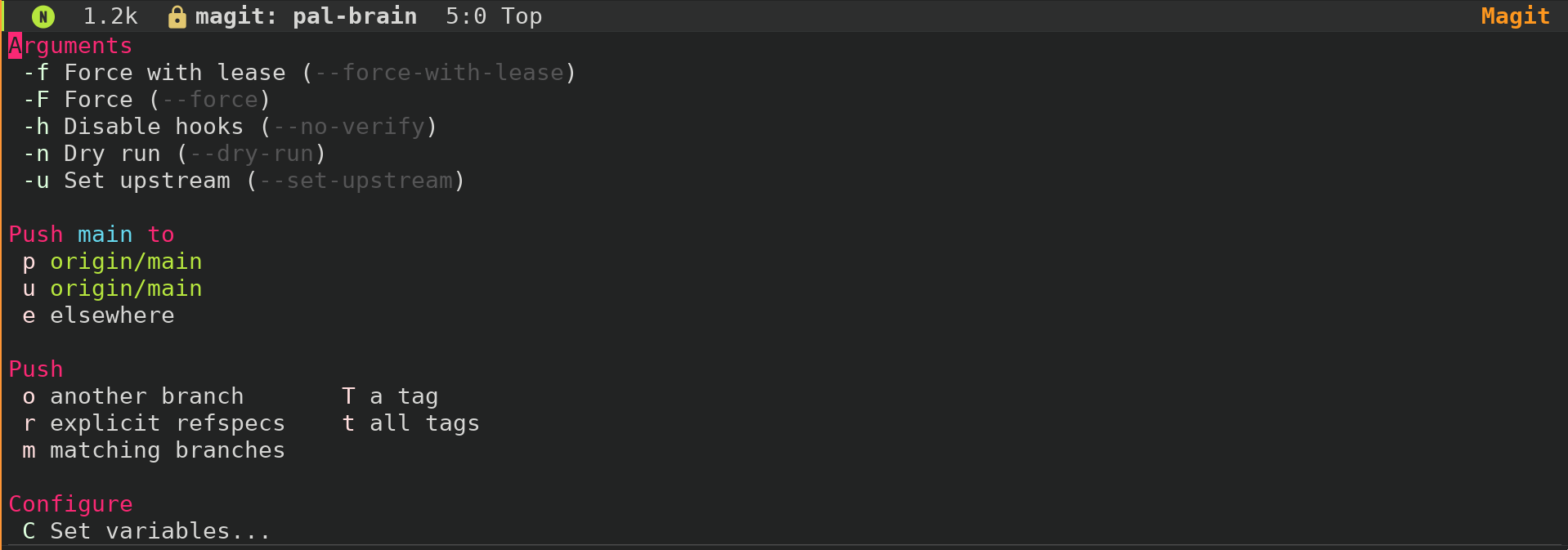
Magit's interface is so great that (by popular demand) they decided to package it separately into a package called transient. Others are invited to use it to build great emacs plugins -- and that's just what I plan to do!
As I was building the acorn-pal-brain backend, I realized that there was a TON of overlap with the needs of this project and the needs of a project I'm building for Mozilla called Memory Cache Hub. The goals of the project are different, but the basic capabilities are extremely similar. A big open question for me will be whether I should keep the two projects separate (which involves a non-trivial amount of duplicate work), or try to combine them in such a way that both acorn-pal-emacs and the Memory Cache Browser Client can use the same backend.
In the meantime, I'm excited to share what I've built out so far...
Acorn Pal Brain is the "server-side" application:
- It exposes APIs used by the emacs client.
- It serves synthesized project artifacts as a static file server.
- It downloads and runs
llamafilesas subprocesses or connects to a remote LLM for inference. - It ingests and retrieves document fragments with the help of a vector database.
- It generates various artifacts using prompt templates and large language models.
Acorn Pal Emacs is the emacs package that adds various commands to call the brain's APIs and will (soon!) provide dedicated buffers for interacting with the brain.
I'm sorry to say that screenshots will have to wait... But not for long! :wink:
FAQ
Does this work with Vim, VS Code, Sublime Text, Text Mate, etc?
The backend process (acorn-pal-brain) does most of the heavy lifting and is agnostic towards clients that interact with it. But at the moment, I only have plans to build an emacs client.
Why Emacs?
I'm not here for holy wars. Emacs is the editor I like to use, and I want to solve my problems before worrying about others.